操作系统基础2
流水线
- SEQ将不同的指令所需的步骤组织成统一的流程,可以用很少的硬件单元以及一个时钟来控制计算的顺序,但是太慢了,不能充分利用硬件单元,引入流水线获得更好的性能
- 猜测分支方向并根据猜测开始取指的技术成为分支检测
- 流水线冒险
- 数据冒险:下一条指令会用到这条指令的计算出的结果,可以用暂停、转发来避免数据冒险
- 控制冒险:一条指令要确定下一条指令的位置,当处理器无法根据处于取指阶段的当前指令来确定下一条指令的地址时会出现控制冒险
- 内存读在流水线中发生的比较晚,将暂停和转发结合起来,避免加载/使用数据冒险,这种方法称为加载互锁
- 按照指令进入流水线的顺序列出,不是按照在程序中出现的顺序,预测跳转指令会出现分支,去除位于跳转指令目标处的指令,在下一个周期取出目标指令后的那条指令,指令到达执行阶段指令会改变条件码,在下一个周期就能取消错误指令(指令排除)
- 异常处理
- 指令集结构包括三种不同的内部产生的异常,halt指令、非法的指令和功能码组合的指令、取指或数据读写试图访问一个非法地址
- 完整的处理器应该能够处理外部异常
- 将导致异常的指令称为异常指令,流水线中越深的指令引起的异常优先级越高
- 在流水线结构中加入异常处理逻辑,状态码Stat,当处于访存或者写回阶段指令导致的异常,流水线控制逻辑必须禁止更新条件码寄存器或数据内存
- 保证第一个出现异常的指令第一个到达写回阶段,此时程序停止
- 性能分析
- 计算PIPE执行一条指令所需要的平均时钟周期数的估计值,来量化冒险产生的性能损失,这种衡量方法称为CPI
CPI=1.0+lp+mp+rp每种处罚都是以该种原因产生的气泡数/执行指令总数Ci,其中load penalty #加载处罚,mispredicited branch penalty #预测错误分支处罚,return penalty #返回处罚
优化程序性能
- 度量标准:每元素的周期数CPE,表示每个时钟周期执行了多少条指令
- 提高性能的方法:消除循环低效率、减少过程调用、消除不必要的内存引用
- 现代处理器
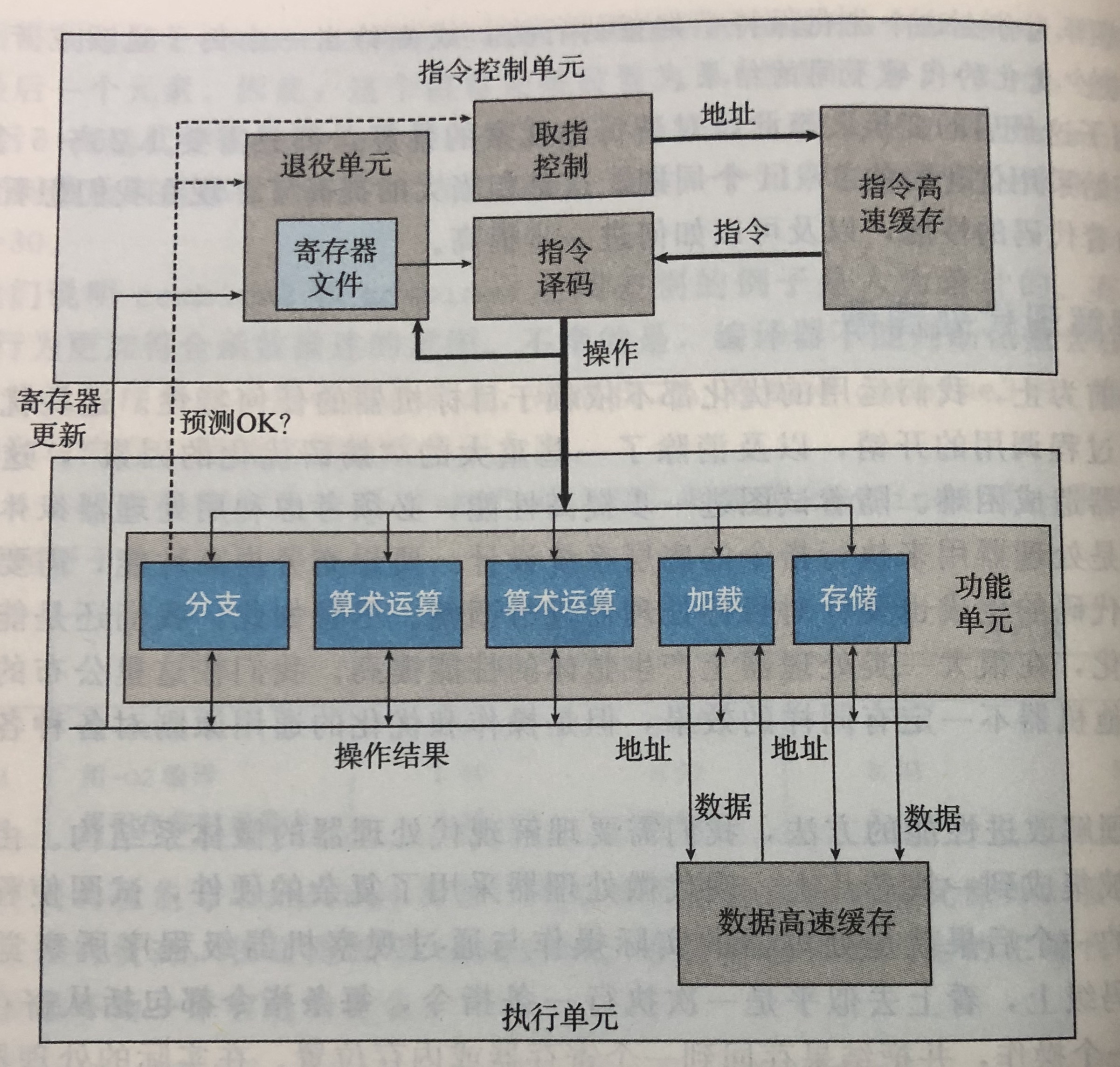
- 在实际的处理器同时处理多条指令,称为指令级并行,会出现延迟界限(在下一条指令开始之前这条指令必须结束)、吞吐量界限(处理器功能单元的原始计算能力)
- 整个处理器主要分为两个部分,指令控制单元ICU和执行单元EU
- 指令译码逻辑接收实际的程序指令,转换为一组基本操作(微操作),EU接收来自取指单元的指令,每个时钟周期可以接收多个操作,这些操作会被分派到一组功能单元中,这些功能单元专门用来处理不同的类型
- 退役单元
- 退役单元记录正在进行的处理,确保遵循机器级程序的顺序语义。
- 其中的寄存器文件包含整数、浮点数、和最近的SSE和AVX寄存器是退役单元的一部分
- 退役单元控制着寄存器的更新,指令译码时,关于指令的信息被放置在一个先进先出的队列中,所有对寄存器的更新只有等指令退役时才会发生
- 指令操作完成且引起这条指令的分支点被确认为预测正确,这条指令退役,所有对程序的寄存器的更新被实际执行
- 或者引起该指令的分支点被确认预测错误。这条指令被清空,丢弃所有计算结果
- 控制操作数在执行单元间传送最常见的机制是寄存器重命名,重命名表只包含关于有未进行写操作的寄存器条目,这种机制可以被认为是一种数据转发

- 功能单元的性能: 运算由以下数值刻画
- 延迟:完成运算需要的时间
- 发射时间:两个连续的同类型操作运算之间需要的最小时钟周期数
- 容量:执行该运算的功能单元的数量
- 用CPE值的两个基本界限来描述算术运算的延迟、发射时间和容量对合并函数的性能的影响,延迟界限给出了任何必须按照严格顺序完成合并运算的函数所需要的最小CPE值,根据功能单元产生结果的最大速率,吞吐量界限给出了CPE的最小界限
- 将可以访问到的寄存器分为4类
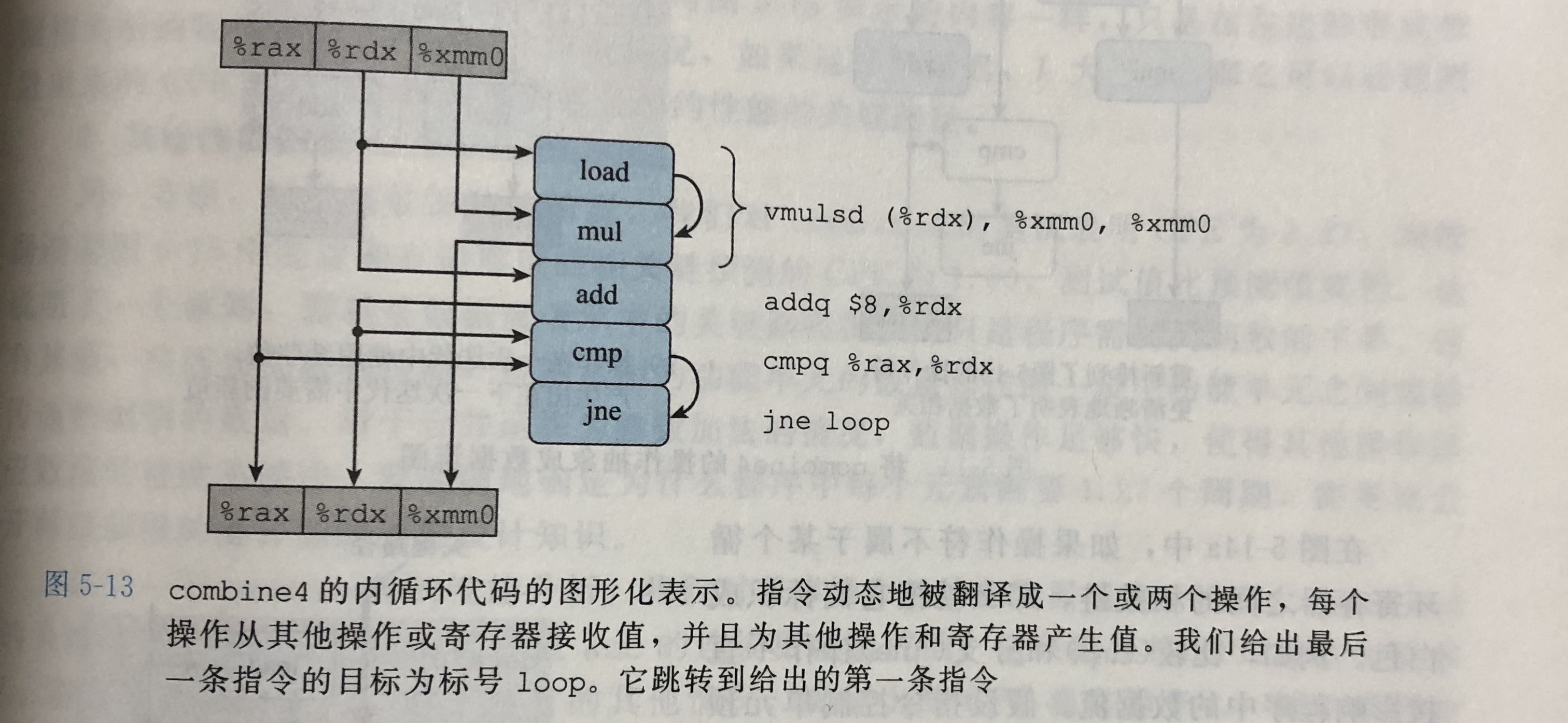
- 只读:只能作为源值,也可以用来计算内存地址,但是在循环中不会被修改,循环combine4中的只读寄存器是%rax
- 只写:作为数据传送操作的目的
- 局部:在循环内部修改和使用,迭代和迭代之间不相关,如上例中的条件码寄存器
- 循环:这些寄存器既作源值也作目的,一次迭代中的值会在另一次迭代中用到,循环combine4中的循环寄存器是%rdx和%xmm0用程序的数据8. 流图形化的分析现代处理器执行的机器级程序性能,可以看到制约程序性能的主要因素是mul的链

- 循环展开通过增加每次迭代的计算的元素的数量来减少迭代次数
- 提高并行性,如:多个累积变量,将累乘分为奇数项乘积和偶数项乘积,称为2*2循环展开(并行执行)
- 程序性能的限制因素:
- 寄存器溢出:循环变量的个数超过了可用的寄存器数量,程序就必须在栈上分配空间,内存的读取比寄存器慢的多
- 分支预测错误:在使用投机执行的处理器中,如果发生预测就要丢弃所有投机执行的结果,在正确的位置重新开始取指令的过程,会引起错误处罚,再重新开始有用的结果之前,必须重新填充流水线。分支预测逻辑会产生很差的性能,使用条件操作来计算值,使用可以表达条件行为的方法,能够直接翻译成条件传送
- 存储单元包含一个存储缓冲区,包含发射到存储单元还没有完成的存储操作的地址和数据,这里的完成包括更新数据高速缓存。提供这样一个缓冲区,使得一系列存储操作不必等待每个操作都更新高速缓存就能执行
- 性能提高技术
- 消除连续的函数调用
- 消除不必要的内存引用
- 低级优化:展开循环降低开销、利用多个累积变量和重新结合等技术找到到方法提高指令集并行、使用功能性的风格重写条件操作
- 重新排列循环以提高空间局部性
- Unix系统提供了一个剖析程序GPROF,产生两种形式的信息:确定程序中的每个函数花费了多少CPU时间、计算每个函数被调用的次数,三个步骤如下:
- 程序必须为剖析而编译和链接,命令行-pg,优化标志-Og确保正确跟踪函数调用
- 程序运行产生文件gmom.out
- 调用GPROF来分析gmon.out中的数据
- GPROF的属性
- 计时不是很准确,计时机制是很简单的间隔计数
- 假设没有执行内联替换,则调用信息相当可靠
- 默认情况下不会对库函数计时
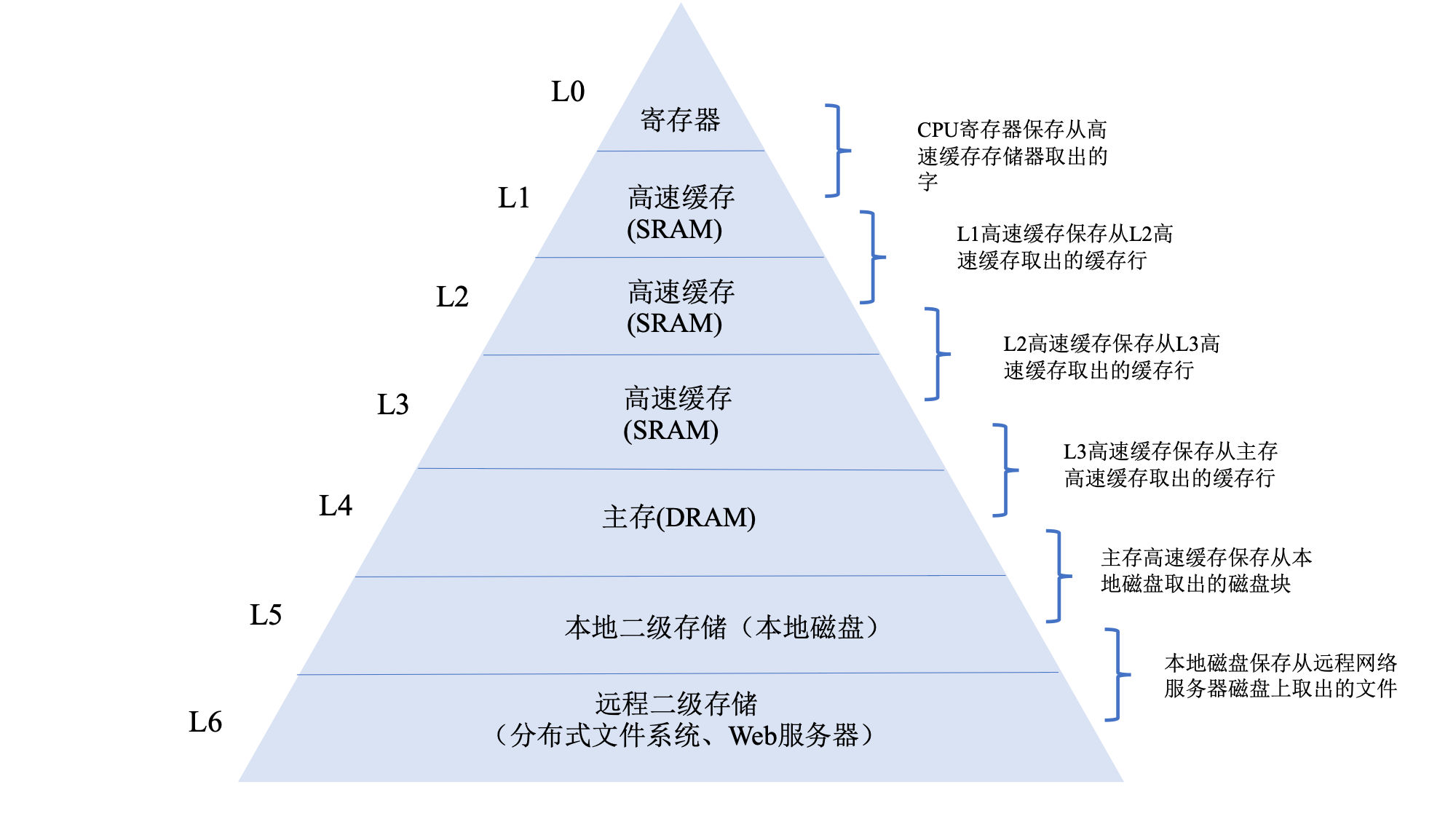
存储器层次结构
- 计算机程序称为局部性的基本属性,具有良好局部性的程序倾向于一次又一次的访问相同的数据项集合,或倾向于访问临近的数据项集合,具有良好局部性的程序更倾向于向存储器层次中较高层次的处访问数据项
- 在硬件层,局部性原理允许计算机设计者通过引入告诉缓存存储器的小而块的快速存储器来保存最近被引用的指令和数据项,提高对主存的访问速度。
- 每隔k个元素访问,称为步长为k的引用模式,随着步长的增加,空间局部性下降。
- 存储器层次结构
将k+1层的存储器划分为连续的数据对象组块,称为块,块可以是固定大小的也可以是可变大小的,将k层划分为较少的块的集合,块的大小和k+1层一样,数据总是以块为大小在第k层和k+1层之间来回复制 - 缓存命中: 程序需要k+1层中的某个数据对象d,首先在k层查找,如果d刚好缓存在k层中,则成为缓存命中
- 缓存不命中: 当k层中没有数据对象d,第k层的缓存从第k+1层缓存中取出包含d的那个块,若k层的块已经满了,则覆盖其中一个块(称为替换或者驱逐),由替换策略来决定替换哪个块。缓存不命中的种类如下:
- k层缓存为空,空的缓存称为冷缓存,此类不命中称为强制不命中或冷不命中
- 发生不命中后,k层缓存必须执行某个放置策略,确定从k+1层取出的块放在哪里,靠近CPU的硬件缓存通常使用更严格的放置策略,将k+1层的某个块限制放置在第k层的一个小的子集中,这种策略会引起冲突不命中
- 按照一系列阶段(循环)来运行,每个阶段访问缓存块的某个相对稳定的集合,这个块的合集称为这个阶段的工作集,工作集的大小超过缓存的大小时,缓存会经历容量不命中
高速缓存存储器
- 高速缓存结构可以用元素(S,E,B,m)来表示:每个存储器有m位,形成M=2^m个地址,机器的告诉缓存被组织成S=2^s个高速缓存组的数组,每个组包含E个高速缓存行,每行有B=2^b字节的数据块组成,一个有效位指明这个行是否包含有意义的信息,t=m-b+s个标记位,唯一的标识存储在高速缓存行中的块,高速缓存的大小时所有块的大小的和C=S×E×B
- 根据每个组的高速缓存行数E将高速缓存分为不同的类,每组只有一行的高速缓存称为直接映射高速缓存
- 高速缓存确定一个请求是否命中分为三步:1)组选择 2)行匹配 3)字抽取
- 直接映射高速缓存中的组选择:选中行
- 直接映射高速缓存中的行匹配:行的有效位设置,得到缓存命中,另一方面,如果有效位没有设置或者标记不匹配得到一个缓存不命中
- 直接映射高速缓存中的字选择:确定所需要的字是从块中哪里开始的
- 直接映射高速缓存中不命中时的行替换:从存储器结构的下一层请求块,将新的块存储在组索引位指示的组中的一个高速缓存行
- 标志位和索引位连起来唯一标识内存中的所有块,多个块映射到同一个高速缓存组,映射到高速缓存组的块由标记位唯一的标识
- 直接映射高速缓存中的冲突不命中:书page431,数组x和y不断交替加载到同一块内存,高速缓存反复加载和驱逐相同的高速缓存组,称为抖动
- 使用中间位作为索引,相邻的块会被映射到不同的高速缓存行
- 写一个已经缓存的字(写命中)
- 可以直写,只写会引起总线流量
- 可以使用写回,尽可能的推迟更新,只有替换算法要驱逐更新过的块时,才写到低一层中,但是这种方法增加了复杂性,高速缓存要额外维护一个额外的修改位
- 处理写不命中
- 写分配:加载低一层的块到高速缓存中,然后更新这个块
- 非写分配:避开高速缓存,直接写到低一层块中
- 直写高速缓存通常是非写分配的,写回高速缓存通常是写分配的
- 真实的高速缓存层次结构的解剖
- 只保存指令的高速缓存称为 i-cache
- 只保存程序数据的高速缓存称为 d-cache
- 既保持指令也保存数据的高速缓存称为统一的高速缓存 unifiled-cache
- 现代处理器包括独立的i-cache和d-cache,i-cache通常只读,比较简单。针对不同的访问模式优化两个高速缓存
- 高速缓存参数的性能影响
- 不命中率、命中率、命中时间、不命中处罚
- 高速缓存大小、块大小、相联度、写策略
- 高速缓存友好的代码
- 局部性比较好的程序更容易有更低的不命中率
- 让最常见的情况运行的更快
- 减少每个循环内部的缓存不命中的数量
